
[Case Study] How Anyreach Approaches Implementation for Agentic AI

![[Case Study] How Anyreach Approaches Implementation for Agentic AI](/content/images/size/w1200/2025/07/ChatGPT-Image-Jul-22--2025--11_23_46-AM.png)
Under the Hood at AnyReach: How We Turn Raw Calls into Safely-Shipped, Data-Driven Voice Agents
Building a world-class VoiceBot isn’t just about stringing ASR, an LLM, and TTS together. At AnyReach we treat the whole lifecycle—from a customer’s first prototype request to live production traffic—as a disciplined, data-centric pipeline. Below is a consolidated look at every layer of that pipeline, weaving in our newest work on language-model datasets, automated evaluation, call simulation, human-in-the-loop safety nets, and the architectural rails that make it all hum.
1 · Implementation Workflow
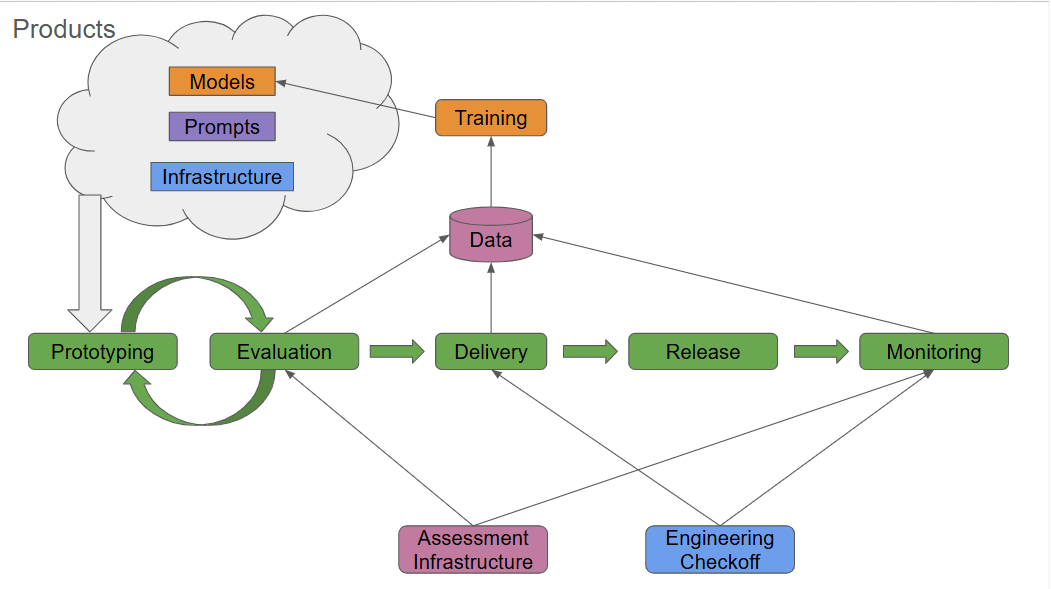
Prototype → Evaluate → Deliver → Release → Monitor → Improve
- Prototype & Evaluate
Rapid builds plus a unified Assessment Infrastructure score every candidate bot on accuracy, tone, latency and more. - Deliver
When metrics turn green, Implementation bundles tagged artefacts and evaluation results into a Delivery package for Engineering. - Release
Engineering re-validates quality, runs scale tests, and publishes a Release to production with formal Release Notes. - Monitor & Improve
Live VoiceBots feed the same assessment engine, closing a tight feedback loop so each new iteration starts smarter than the last.
2 · Language-Model Dataset Generation
| Stage | What Happens | Quality Guards | Why It Pays Off |
|---|---|---|---|
| Ingestion & Tagging | Dual-channel recordings flow into secure storage; call metadata (bot ID, scenario tag, language guess, consent flag) is attached up-front. | Rejects if consent flag missing or audio SNR < 18 dB. | Clean pipeline = zero downstream rework. |
| Speaker-Aware Transcription | A diariser labels each utterance with user / assistant and millisecond timestamps. | Spot-audit WER on 2 % sample; auto-flag if WER > 15 %. | High-fidelity turns → better intent distribution. |
| Conversation Structuring | Utterances convert to a JSON chat schema:[{role:"user", text:"…"},{role:"assistant", text:"…"}] | Schema validator checks turn order, empty strings, emoji encoding. | Ready-made for any modern chat model. |
| System-Prompt Derivation | An LLM summarises tone, domain, and policies into a reusable system prompt (multilingual when detected). | Alignment check ensures no PII or brand-unsafe claims sneak in. | Auto-boots new bots in hours, not days. |
| Batching & Redaction | Conversations batch into 100–500 turn packs with hashed IDs, audio URLs, and prompt type. Optional PHI redaction via regex + ML NER. | Redaction audit on 1 % of health calls; error budget ≤ 0.1 %. | Lets us ship HIPAA-safe fine-tunes to GPU farm with one command. |
| Catalog & Search | Indexed by language, use-case, sentiment, task outcome, and error codes. | Daily index integrity check. | Data scientists can pull “Spanish pharmacy refills, negative sentiment” in seconds. |
Result: a living corpus that fuels prompt-tuning, supervised fine-tuning, and eval-set refreshes—all with baked-in privacy controls.
3 · Automated LLM Evaluation
| Layer | What Happens | Model Loss Function |
|---|---|---|
| LLM Training | Fine-tune or prompt-tune for the target use-case. | – |
| Auto Evaluation | Simulated conversations graded by an LLM judge. | Turn-level relevance, task success, policy adherence |
| Human Review | QA analysts audit flagged outliers. | Pass/fail, qualitative notes |
| Bot-Stack Eval | End-to-end latency, VAD accuracy, transfer logic, etc. | Composite AVM Score |
All steps are live and running in production today.
4 · Scenario & Conversation Simulations
Scenario and conversation simulations are our “wind tunnel” for VoiceBots: they let us expose new prompts, policies, or models to thousands of realistic conversations—offline, overnight, and at virtually zero cost—so only the toughest, fully-vetted version ever reaches production.
4.1 Two Complementary Simulation Modes
| Mode | How We Build It | Typical Use-Cases | Key Benefits |
|---|---|---|---|
| Reference-Free Scenarios | Prompt an LLM user-simulator with personas, goals, mood, and optional constraints. txt You are an impatient caller who refuses to share their DOB until trust is established. | • Early-stage edge-case hunting • Stress-test new policies (e.g., HIPAA, GDPR) • Tone/rapport experiments | Unlimited diversity, instant creation, no real data needed. |
| Reference-Based Replays | Feed the simulator turn-by-turn transcripts from real human calls; the model mimics each caller’s exact wording, timing, and sentiment. | • Regression testing before prompt rollback • A/B comparisons of candidate prompts • Replicating bugs reported from the field | True-to-life acoustics, accents, hesitations—captures the “messiness” we actually face in production. |
Both modes can run in text-only (sub-second feedback loop) or voice bot-to-bot (full TTS + ASR, perfect for latency and audio-quality checks).
4.2 Simulation Workflow in Detail
- Scenario Library Curation
Product and QA teams maintain YAML/JSON scenario files:yamlCopyEditid: appt-cancel-spanish-vm]
persona: "Spanish-speaking parent, driving, noisy background"
goal: "Cancel child’s dental appointment and confirm reschedule date"
must_test: [voicemail_detection, language_switch
– Every new production bug or feature request spawns a fresh scenario file so coverage keeps expanding. - Automatic Parameterisation
Templates inject random but bounded variables (names, dates, policy numbers) to avoid over-fitting while staying domain-correct. - Simulation Engine Kick-off
CI pipeline triggers nightly or on every pull request:
Scenario X × Prompt Version Y × Model Z → matrix of runs executed in parallel containers. - Real-Time Hooks
During voice sims we stream audio through the same telephony stack as production, so we catch synthesis glitches, VAD misfires, and end-of-utterance clipping exactly as they would happen live. - Metric Harvesting & Comparison
Each run returns:- Turn-level scores (relevance, tone, latency)
- Conversation-level scores (task success, containment, policy compliance)
- Raw artifacts (audio, JSON logs) for ad-hoc triage.
A cantera-style diff highlights regressions versus the current gold standard.
- Fail-Fast Gates
- Merge blocked if any critical metric dips.
- Severity-weighted dashboard pinpoints which scenario + metric combo broke.
- One-click repro link re-launches the failing sim locally for rapid debugging.
4.3 Putting Simulations to Work
| Phase | How Simulations Help |
|---|---|
| Prompt Ideation | Designers try bold wording changes in text sims first; only the best variations graduate to voice sims. |
| Model Upgrades | Swap in a larger-context LLM, rerun 10 k historical calls overnight, and green-light the upgrade the next morning—no live traffic needed. |
| Localization QA | Generate persona files in French, Spanish, and Mandarin; confirm language detection, polite forms, and cultural norms before launching in new regions. |
| Regulated Deployments | Create “red-team” scenarios (e.g., suicidal ideation, prescription misuse); verify mandatory escalations fire 100 % of the time. |
| Capacity Planning | Voice sims measure TTS & ASR GPU usage under load, informing infra auto-scaling thresholds. |
4.4 Why It’s a Game-Changer
- Days of manual QA → minutes of automated coverage
- No telephony bills while still exercising the full audio stack
- Deterministic repro of rare field bugs—just rerun scenario #547
- Data-privacy safe: reference-free sims need zero customer recordings
- Direct feedback loop into prompt refiner: the Auto Prompt Refiner scores new wording in sims, tweaks again, and repeats until the Anyreach Voicebot Metric (AVM) score plateaus (more details to follow on this).
(Optional) Voice Creation — Training, Cloning, and Actor Collaboration
A. Choosing the Voice
- Business persona workshop – define brand tone (warm, authoritative, playful, etc.).
- Actor search & interview – assess linguistic range, studio quality, and willingness to iterate (sample script, live test call).
- Contract & milestones – fixed deliverables (clean WAVs, pick-up rounds) keep scope tight and timelines predictable.
B. Data Collection Guidelines
| Rule | Rationale |
|---|---|
| Record in a quiet, treated space | Even faint HVAC noise degrades cloning fidelity. |
| 30 min of pristine audio beats 2 h of mediocre | Quality > quantity for model convergence. |
| Use single-speaker, continuous speech | Multi-speaker chatter or micro-clips confuse the model. |
| Match the target context | Recording customer-support phrases for a support bot yields a more believable clone than reading fairy tales. |
C. Model Building Options
| Path | Typical Input | Turnaround | Best For |
|---|---|---|---|
| Zero-shot cloning | 20–30 s reference clip | Minutes | Rapid demos & A/B voice tests |
| Fine-tuned TTS | 30 min curated audio | ~1 day | Production-grade brand voice |
| Custom actor pipeline | Actor + studio sessions | ~1 week incl. pick-ups | Flagship marketing or regulated domains |
All voices pass through subjective listening tests (naturalness & brand fit) and an objective MOS (Mean Opinion Score) benchmark before going live.
D. Iteration Loop with the Actor
- Replay real test calls in working sessions.
- Prompt surgery on the spot – split long sentences, add SSML pauses, tweak pronunciation tags.
- Re-record only the deltas – avoids large re-takes and speeds approval.
- Freeze version tag once the bot survives edge-case stress tests.
Outcome: a cloned or actor-recorded voice that feels human, stays on-script, and can be re-generated instantly for future content.
5 · Replay-Driven Prompt Safeguards
We routinely re-run thousands of real production calls through current-vs-candidate prompts, gate new versions behind automated scores and human spot-checks, then shadow them on live traffic before full rollout. Safety and speed, no compromise.
- Snapshot Live Traffic
Every 24 h we sample fresh production calls (balanced by scenario and language) and convert them to the chat schema above. - A/B Simulation Runs
Current prompt vs. candidate prompt each replay the identical caller turns in a sandbox. Replaying the exact caller turns from a past call isn’t reliable, because even slight changes in how the VoiceBot responds—like a different greeting or answer—can shift the entire conversation flow. Instead, we simulate conversations intelligently, adapting the caller’s behavior to fit the bot’s real-time responses. - Multi-Layer Scoring
LLM judge returns granular metrics (clinical safety, policy hits, empathy, task success). Separate rule-checker hunts for hard violations (PHI leak, profanity, regulatory wording). - Auto-Rollback
If any red flag (e.g., emergency triage error) breaches thresholds, traffic snaps back to the last stable prompt in under two minutes.
Gate Criteria
| Gate | Pass Rule |
|---|---|
| Local metric gate | Candidate ≥ current on all critical scores |
| Human audit | Analysts review worst-5 % scored dialogs |
| Shadow mode | Prompt runs silently on live calls for 24–48 h; discrepancies logged only |
| Traffic ramp | 10 % → 50 % → 100 % once CSAT & escalation stable |
Net effect: weekly prompt refreshes with zero production surprises.
6 · Human-in-the-Loop Transfers
| Flow Step | Details | Monitored KPI |
|---|---|---|
| Trigger Detection | Rules (keyword, intent, sentiment) and Judge/Monitor Model Flags Call as at Risk | False-positive rate < 3 % |
| Transfer Negotiation | Bot says: “Let me connect you with a colleague who can help.” Holds music if wait > 5 s; reassures every 20 s. | Abandon rate during hold < 2 % |
| Context Handoff | Bot packages transcript summary, key slots, sentiment score, and caller phone # in structured payload to the agent desktop. | Data-loss incidents = 0 |
| Fallback Handling | If no agent free in 15 s, bot offers callback or voicemail and logs the failure cause. | First-human-voice ≤ 4 s on 99 % calls |
| Analytics & Retraining | Every transfer tagged HITL_TRANSFERRED with reason code (OOS intent, policy risk, user request). Weekly review feeds new intents and prompt fixes. | Post-transfer CSAT ≥ 4.5/5 |
Outcome: callers never get stuck, while transfer logs become a goldmine for expanding bot coverage.
- Seamless cold or warm hand-offs in < 2 s.
- Full context stitched through to the human agent and logged for training.
- Post-transfer CSAT ≥ 4.5/5 and 99.9 % transfer success.
7 · Quality Monitoring & Reporting
Every call is auto-scored on — grounding, relevance, empathy, latency, task completion, business KPIs — and surfaced in dashboards with playable audio for rapid audits.
AnyReach tracks a balanced scorecard that blends technical precision, conversational finesse, and business impact. Every production call is automatically scored, stored, and surfaced in dashboards—so stakeholders can trace improvements straight to ROI.
| Dimension | Representative Metrics | Why It Matters |
|---|---|---|
| Speech Tech | • Latency (user-speech-to-response) • Back-channel cadence • Interrupt-recovery time • Voice naturalness index | Fast, natural audio keeps callers engaged and signals professionalism. |
| Conversation Flow | • Task-completion rate • Turns-to-resolution • Containment rate (no human hand-off) | Shows whether the bot actually gets the job done and how efficiently. |
| Grounding & Relevance | • Factual-accuracy score • Context-retention score • Response-relevance rating | Confirms that answers are correct, on-topic, and consistent across turns. |
| Harm & Safety | • Escalation protocol adherence • PII-handling accuracy • Empathy / stress-induction score | Protects users, brands, and sensitive data—vital in healthcare and finance. |
| User Experience | • CSAT / NPS / CES • Hang-up rate • Barge-in & repeat rates | Direct signal from the people who matter most: end users. |
| Business Impact | • Cost per interaction • Call-deflection rate • Appointment show-rate / conversion rate | Links VoiceBot performance to bottom-line outcomes. |
Assessment pipeline
- Raw call ingestion → transcripts, embeddings, and acoustic features land in our analytics store.
- Metric engines (LLM graders, signal-processing jobs, rule checks) score each dimension.
- Edge scoring compares automated grades to periodic human labels, maintaining ground truth.
- Dashboards & alerts give teams real-time views and weekly roll-ups (accuracy deltas, emerging issues, A/B test winners).
The same framework scales from a single dental-appointment bot to an enterprise contact-centre fleet—all with zero manual spreadsheet work.
8 · Voice Activity Detection & Turn-Taking
Domain-specific VAD and turn-taking models reduce double-talk events by 90 % while keeping bots responsive in noisy environments.
| Challenge | Our Solution | Impact Metrics |
|---|---|---|
| False starts in noisy rooms | Domain-tuned VAD trained on 8 kHz healthcare & retail calls; additive noise augmentation improves robustness. | 50 % drop in bot “double-talk” incidents |
| Over-talking the user | Router model weighs VAD, ASR confidence, and conversational state to decide when the bot may speak. Prompts can tweak aggressiveness on the fly. | 90 % reduction in user-bot overlap |
| Long awkward silences | Adaptive timeout varies by user speech rate and prior latency history; back-channel tokens (“mm-hmm”) keep the floor. | Avg perceived latency −320 ms |
| Multi-speaker environments | Energy-based localisation plus speaker embeddings suppress non-target voices (TV, side-talk). | ASR error rate from background chatter −35 % |
| Cross-language responsiveness | Separate VAD profiles per language cluster auto-selected via language ID; prevents mis-fires from tonal languages. | Turn accuracy parity across 30+ languages |
Evaluation Loop
Turn-taking accuracy is scored nightly: we label 1 % of traffic for true speaker boundaries and measure precision/recall. If recall dips < 95 %, the model retrains on the latest dual-channel calls—keeping behaviour aligned with real-world acoustics.
9 · Capability-to-Use-Case Map (Why It Matters to You)
Below is a customer-centric view of our live capability set. Match your business goal on the left to the capabilities on the right and you’ll see we’ve got you covered.
| Typical Customer Need | Relevant AnyReach Capabilities | Outcome Delivered |
|---|---|---|
| Automate appointment confirmations & reminders | 1 Call-to-Prompt 4 Pre-Call Variables 12 Voicemail Detection | 90 %+ confirmation success, no-show rate slashed |
| Outbound lead qualification for sales | 5 Scenario Generation & Sims 6 Voice-Sim Regression 9 AVM Score | Faster prompt iteration → higher conversion, consistent brand tone |
| 24/7 healthcare triage with clinical safety | 3 Post-Call Transcript Analysis 8 Auto Prompt Refiner 11 HITL Transfers | Safe escalation, HIPAA-grade logging, empathetic conversations |
| Multilingual customer support | 2 Multilingual Dataset Pipeline 17 Custom LLM Fine-Tuning 15 Back-Channeling | Natural-sounding agents in 30+ languages, improved CSAT |
| Quality-at-scale auditing (contact-centre) | 18 Turn-Taking Evaluation 7 Quality Dashboards 9 AVM Score | Human-level QA coverage at a fraction of the cost |
| Brand-specific voice for marketing | 13 Zero-Shot Voice Clone 14 Fine-Tuned TTS | Unique, on-brand voice live in days |
| Risk-free prompt / model updates | 10 Production Call Re-Simulation AVM Score gating | Zero regressions, data-backed rollouts |
Legend – capability IDs reference the full list:
1 Call-to-Prompt · 2 Multilingual Dataset Generation · 3 Post-Call Analysis · 4 Pre-Call Variables · 5 Scenario Generation · 6 Voice Simulation · 7 Dashboards & Monitoring · 8 Auto Prompt Refiner · 9 AVM Score · 10 Call Re-Sim · 11 HITL Transfers · 12 Voicemail Detection · 13 Zero-Shot Voice Clone · 14 Fine-Tuned TTS · 15 Back-Channeling · 16 RouterLLM · 17 Custom LLM Fine-Tuning · 18 Turn-Taking Eval · 19 Noise-Robust VAD · 20 Web-Agent Handoffs
10 · High-Level Architecture (Tool-Agnostic View)
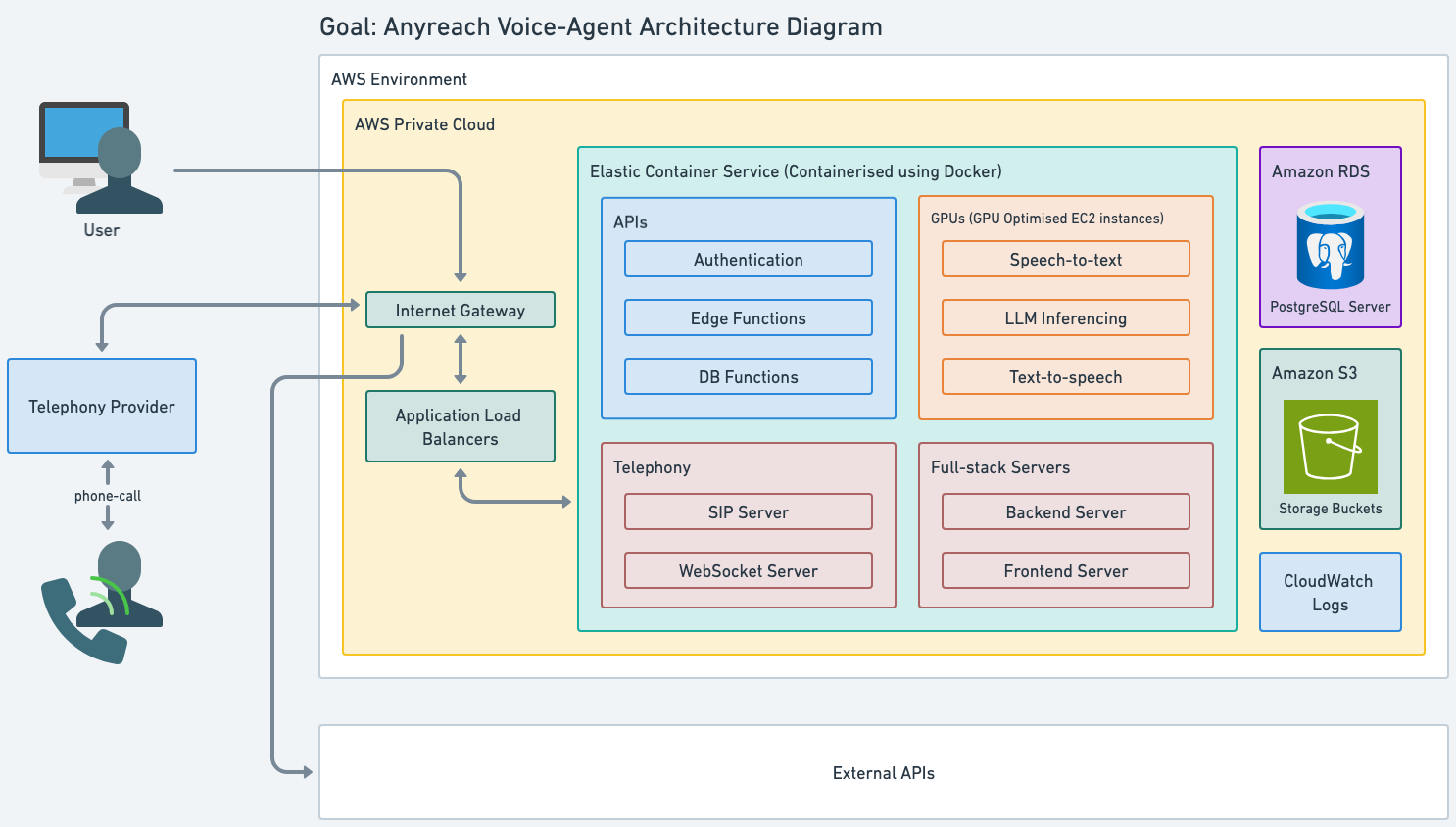
- Telephony Gateway – Manages inbound/outbound call streams.
- Real-Time Audio Pipeline – Speech-to-Text → LLM orchestration → Text-to-Speech on dedicated compute.
- APIs & Event Bus – Orchestrates logging, scoring, and external system integrations.
- Storage – Secure object and relational stores for audio, transcripts, metrics.
- Monitoring & Alerting – Full-stack observability wrapped in SLAs.
All components are fully HIPAA compliant and horizontally scalable.
Key Takeaways
- Data-driven from day one – Every call fuels training, evaluation and optimisation.
- Automation + Human Judgment – LLM judges handle scale, humans handle nuance.
- Safety Nets Everywhere – Replay-based gating and HITL transfers keep risk near zero.
- Capability Breadth – From zero-shot voice cloning to turn-taking analytics, the platform spans the majority of business use cases out-of-the-box.


![[AI Digest] Agents Coordinate Plan Deploy Scale](/content/images/size/w600/2025/07/Daily-AI-Digest.png)